StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
† Project lead, corresponding to xuchenfeng@berkeley.edu
* This work was done when Tianrui Feng visited UC Berkeley, advised by Chenfeng Xu.
Video 1. From top-left to bottom-right: Reference video, StreamDiffusion, Causvid, StreamDiffusionV2.
Prompt: A futuristic boxer trains in a VR combat simulation, wearing a glowing full-body suit and visor. His punches shatter holographic enemies made of pixels and data streams, while the digital environment shifts between glitching neon arenas and simulated landscapes.
Video 2. From top-left to bottom-right: Reference video, StreamDiffusion, Causvid, StreamDiffusionV2.
Prompt: A highly detailed futuristic cybernetic bird, blending avian elegance with advanced robotics. Its feathers are metallic plates with iridescent reflections of blue and purple neon lights, each joint covered by intricate mechanical gears and wires. The eyes glow with a pulsating red core, scanning the environment like a high-tech sensor. The wings expand with layered steel feathers, partially transparent with holographic circuits flowing through them. The bird is perched on a glowing cyberpunk rooftop railing, with a vast futuristic city in the background filled with holographic billboards, flying drones, and neon-lit skyscrapers. The atmosphere is cinematic, ultra-realistic, and science-fiction inspired, combining photorealism with a high-tech futuristic style.
Abstract
Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token–guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1–4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs. Even when increasing denoising steps to improve quality, it sustains 31.62 FPS (14B) and 61.58 FPS (1.3B), making state-of-the-art generative live streaming practical and accessible—from individual creators to enterprise-scale platforms.
Online Streaming Video2Video Transformation
StreamDiffusionV2 robustly supports fast-motion video transfer.
Left: CausVid adapted for streaming. Right: StreamDiffusionV2. Our method maintains style and temporal consistency to a much greater extent. All demos are running on a remote server, and the slight stuttering in the videos is due to network transmission delays (50-300 ms).
StreamDiffusionV2 robustly supports diverse and complex prompts.
Animal-Centric Video Transfer, let your pet begin Live Stream!
StreamDiffusionV2 is ready for your pets real-time Live Stream, the video is captured directly from a camera and processed in real-time for pet youtuber!
Human-Centric Video Transfer, let's begin your Live Stream!
StreamDiffusionV2 is ready for your real-time Live Stream, the video is captured directly from a camera and processed in real-time for youtuber!
Motivation

Fig. 1: Comparison between Batch and Streaming video generation.
Real-time video applications span diverse use cases with widely varying budgets for frame rate, resolution, latency, and motion. This heterogeneity shifts performance bottlenecks across different stages of the pipeline. We highlight four key bottlenecks below..
Unmet Real-time SLOs
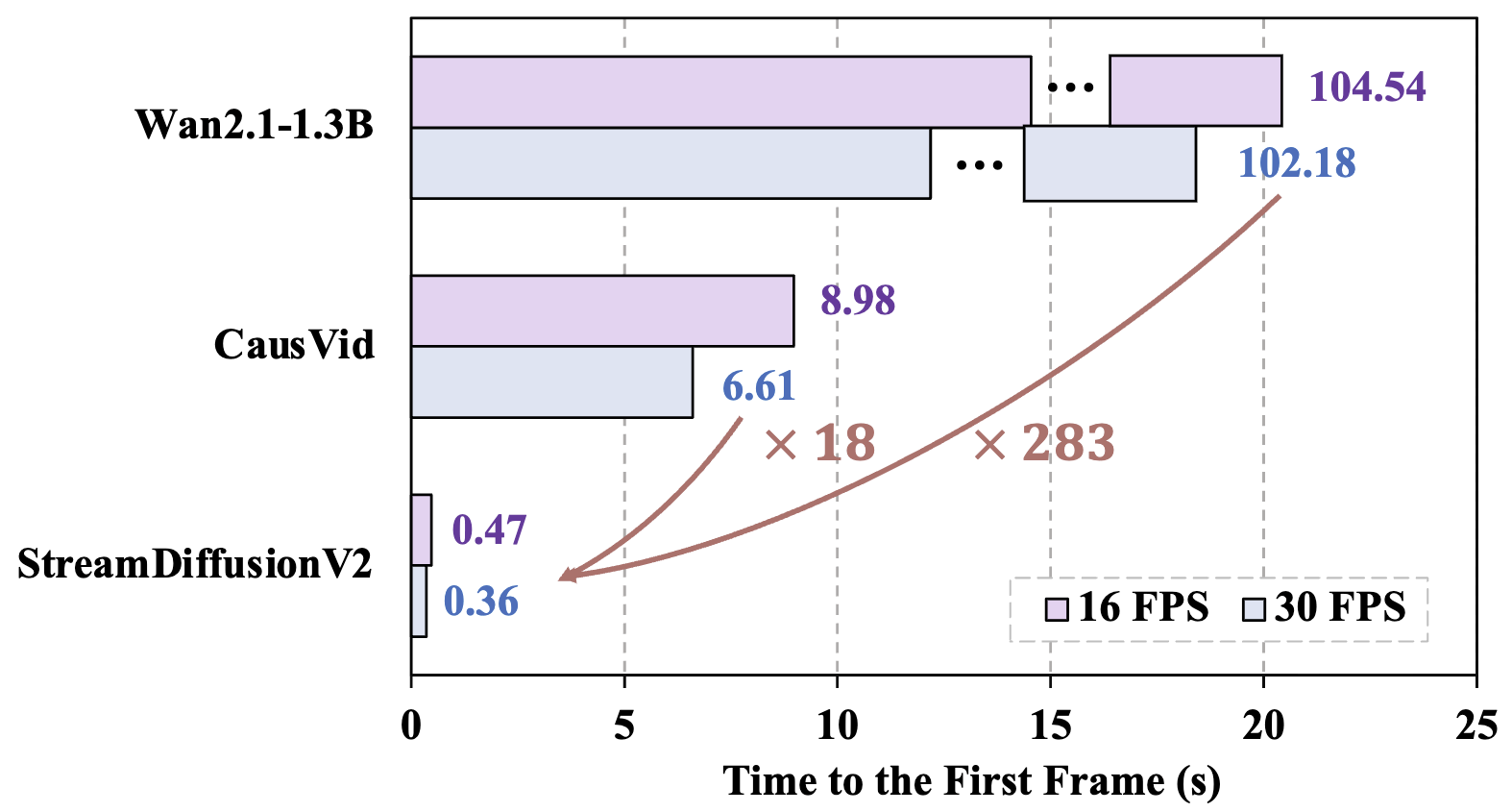
Fig. 2: Time to the first frame on H100 GPU.
Existing streaming systems adopt a fixed-input strategy, processing tens to hundreds of frames per forward pass to maximize throughput. For instance, CausVid and Self-Forcing process 81 frames per step. While this large-chunk design improves average throughput in offline settings, it fundamentally conflicts with the requirements of real-time streaming. We test the time to the first frame (TTFF) of these systems on an H100 GPU that the prior methods far exceed the required TTFF (about 1s), as shown in Fig. 2.
Drift Accumulation in Long-horizon Generation
Current “streaming” video systems are primarily adapted from offline, bidirectional clip generators. For example, CausVID derives from CogVideoX, and SelfForcing builds on Wan-2.1-T2V. These models are trained for short clips (5–10 seconds) and maintain coherence only within that range (see in Video 2).
Quality Degration due to Motion Unawareness
Different motion patterns in the input stream impose distinct tradeoffs between latency and visual quality. Fast motion requires conservative denoising to prevent tearing, ghosting, and blur, whereas slow or static scenes benefit from stronger refinement to recover details. Existing streaming pipelines rely on fixed noise schedules that ignore this variability, leading to temporal artifacts in high-motion regions and reduced visual fidelity in low-motion segments (see in Video 1).
Poor GPU Scaling
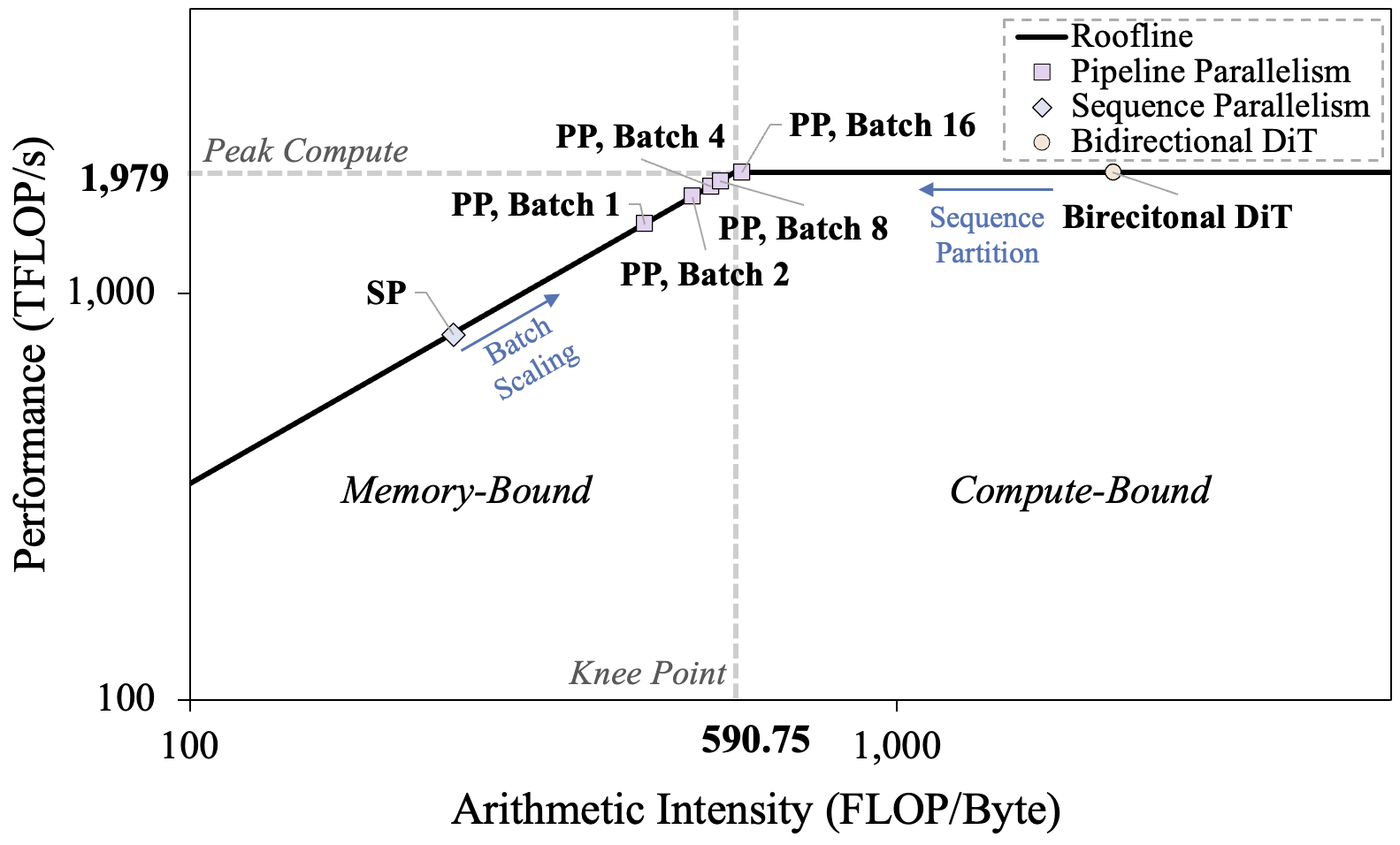
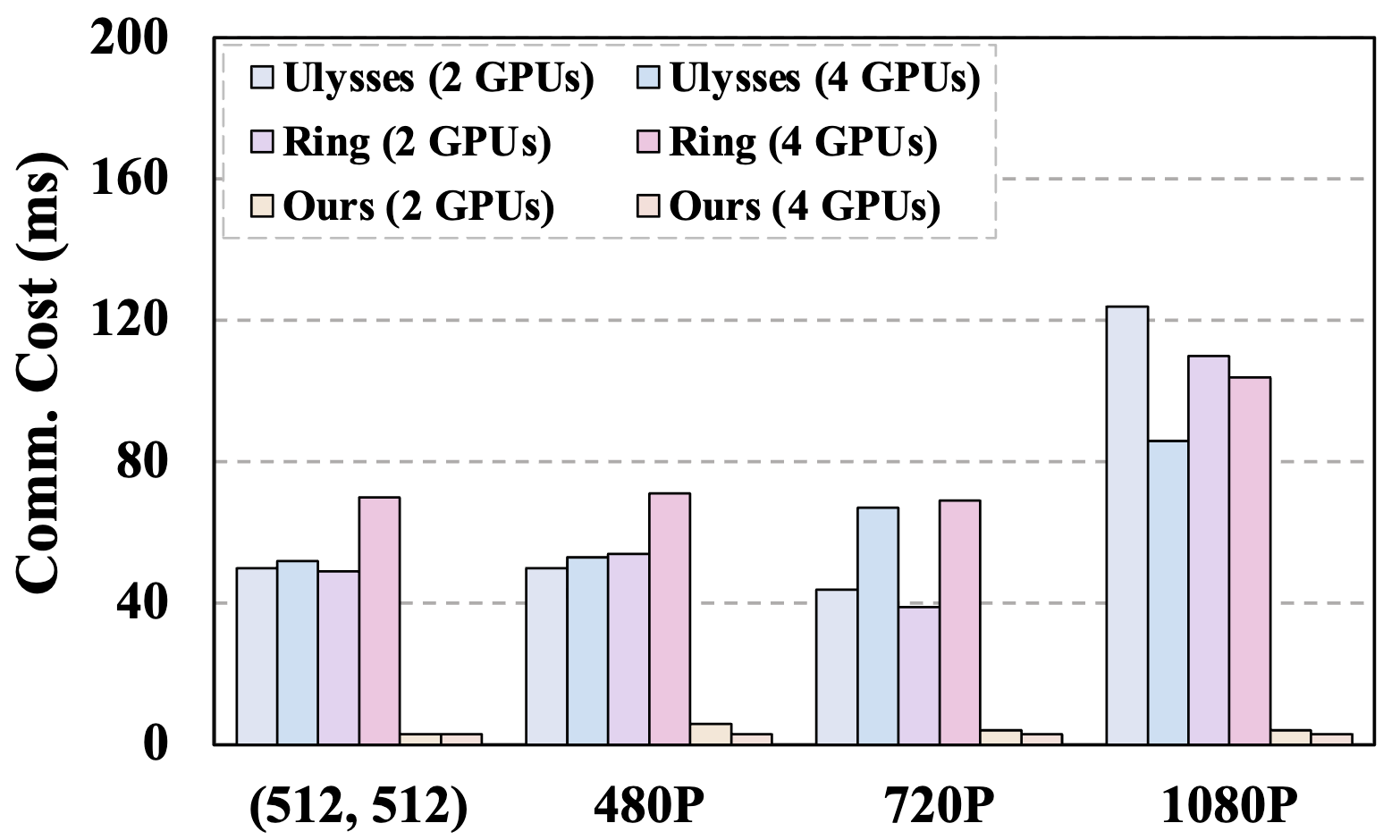
Fig. 3: Left: Roofline analysis of sequence parallelism and our pipeline orchestration. Right: Communication consumption of various parallelism methods.
In live-streaming scenarios, strict per-frame deadlines hinder the scalability of conventional parallelization strategies for two key reasons: (i) communication latency in sequence parallelism significantly reduces potential speedup, and (ii) short-frame chunks drive the workload into a memorybound regime, as shown in Fig. 3, left. These effects are further amplified in real-time streaming, where efficient causal DiTs operate on short sequences (e.g., 4 frames per step), reducing per-frame computation and making communication overhead proportionally heavier (see Fig. 3, right).
Methods
Stream-living pipeline
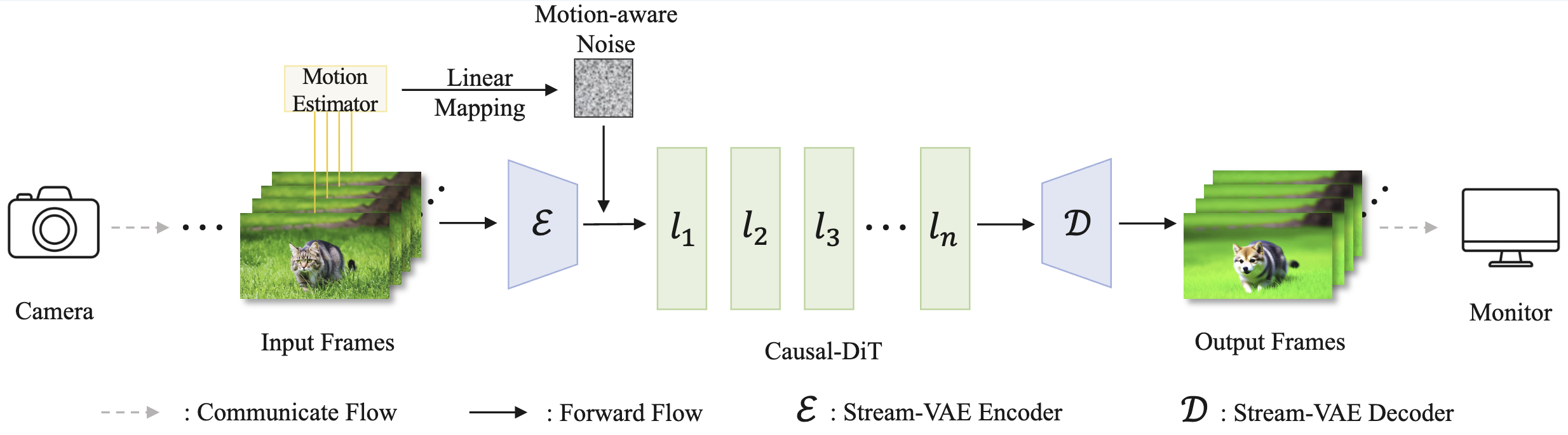
Fig. 4: The overview pipeline of our StreamDiffusionV2.
StreamDiffusionV2 is a synergy of system- and algorithm-level efforts to achieve stream-living based on video diffusion models. It includes: A dynamic scheduler for pipeline parallelism with stream batch, a StreamVAE and rolling KV, and a motion-aware controller.
Rolling KV Cache and Sink Token
We integrate Causal-DiT with Stream-VAE to enable live-streaming video generation. Our rolling KV cache design differs substantially in several aspects: (1) Instead of maintaining a long KV cache, we adopt a much shorter cache length and introduce sink tokens to preserve the generation style during rolling updates. (2) When the current frame's timestamp surpasses the set threshold, we reset it to prevent visual quality degradation from overly large RoPE positions or position indices exceeding the encoding limit. These mechanisms collectively enable our pipeline to achieve truly infinite-length video-to-video live-streaming generation while maintaining stable quality and consistent style.
Motion-aware Noise Controller
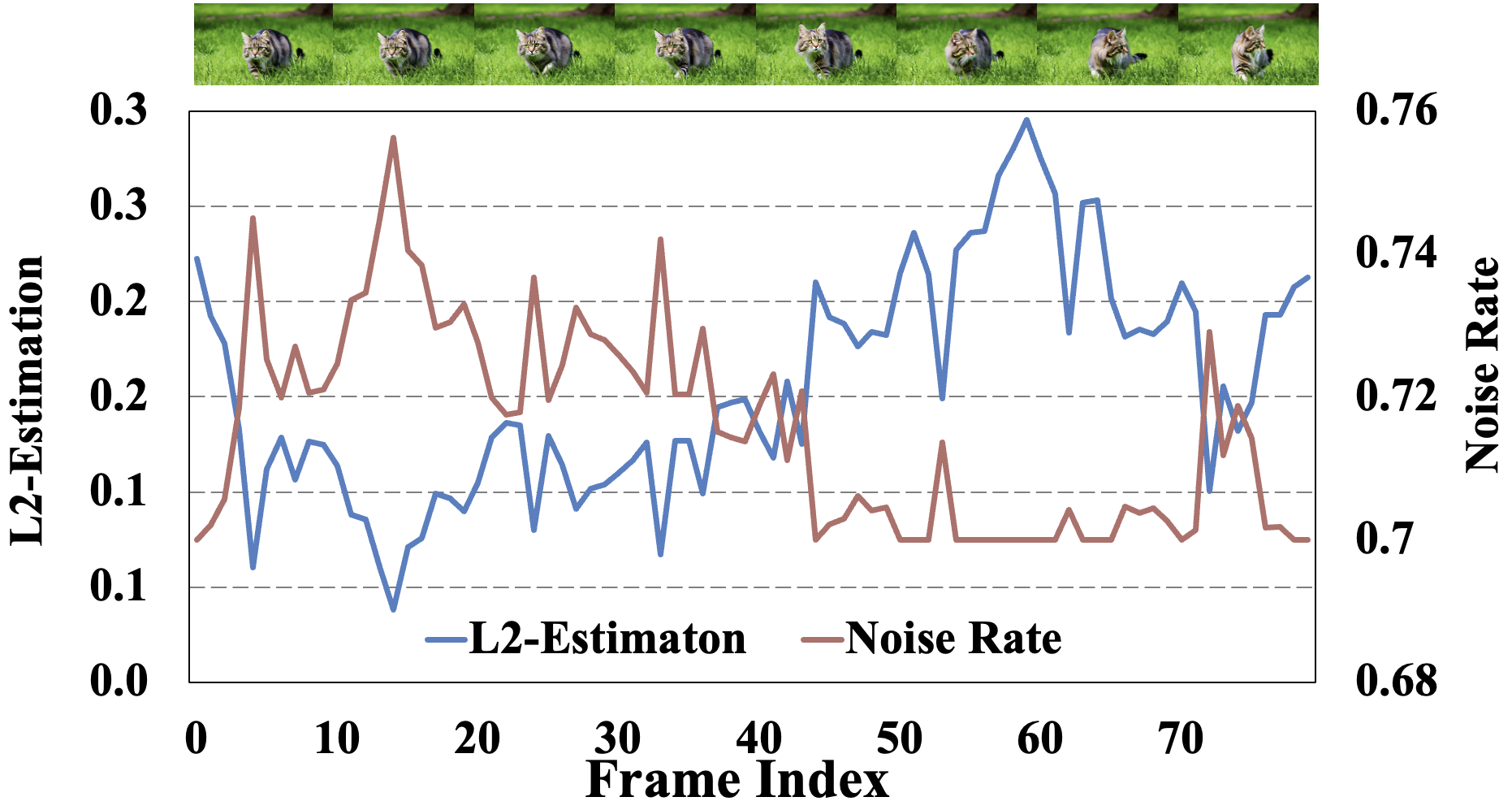
Fig. 5: The overview pipeline of our StreamDiffusionV2.
In live-streaming applications, high-speed motion frequently occurs, yet current video diffusion models struggle with such motion. To address this, we propose the Motion-aware Noise Controller, a training-free method that adapts noise rates based on input frame motion frequency. Specifically, we assess motion frequency by calculating the mean squared error (MSE) between successive frames and linearly map this to a noise rate using pre-determined statistical parameters. This method balances quality and movement continuity in live video-to-video live streaming.
Stream-VAE
Stream-VAE is a low-latency implementation of Video VAE for real-time video generation. Unlike current approaches, which process long video sequences and introduce significant latency, Stream-VAE handles a small video chunk each time. Specifically, four video frames are compressed into a single latent frame during the process. In addition, the cached features are utilized in every 3D convolution module of the VAE to maintain temporal consistency. Stream-VAE ensures temporal consistency while supporting efficient live streaming generation.
Multi-Pipeline Orchestration Scaling
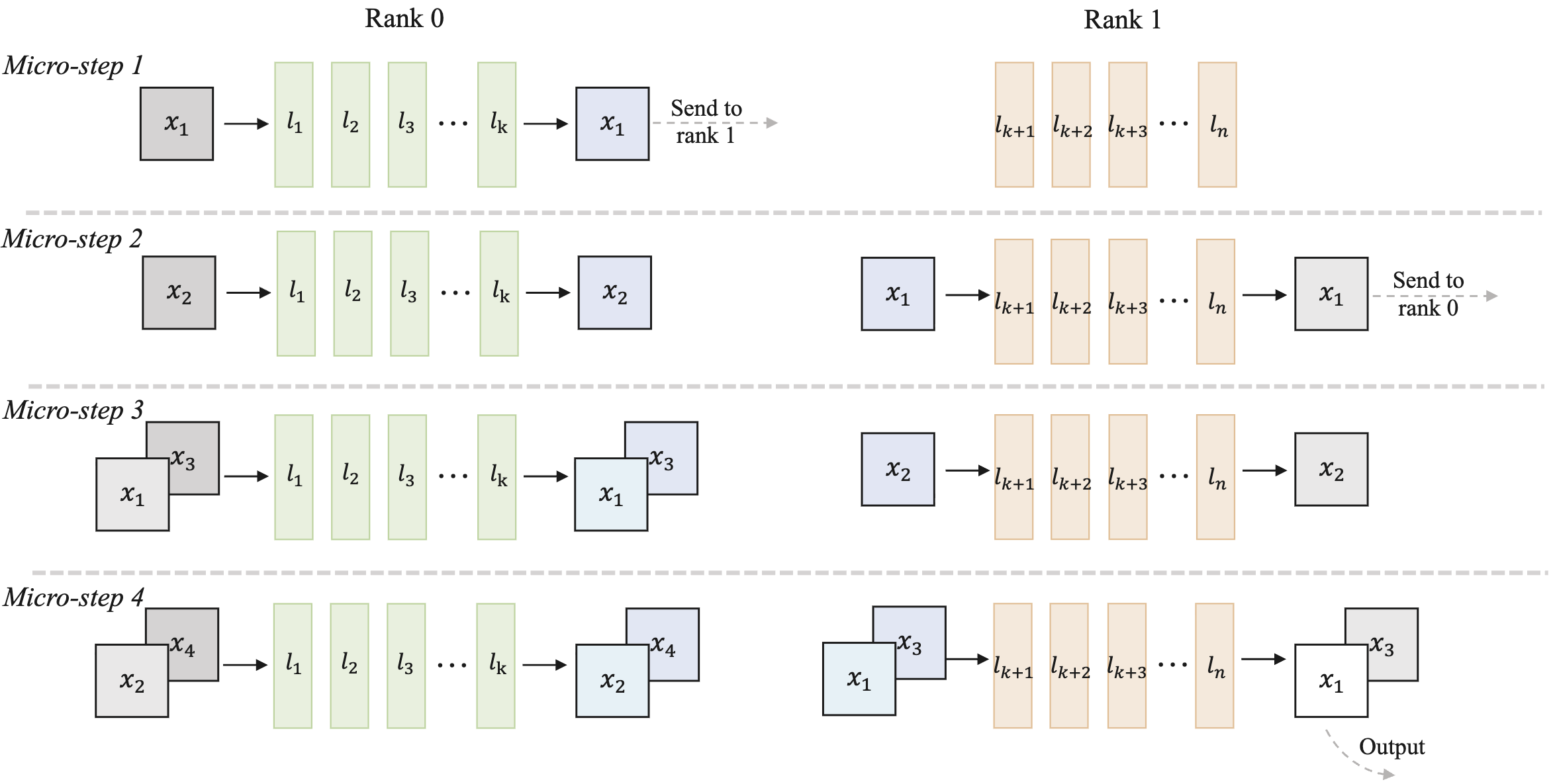
Fig. 6: The detailed description of our Pipeline-parallelism Stream-batch architecture.
Video. 3: An example of Pipeline-parallelism Stream-batch.
To improve system throughput on multi-GPU platforms, we propose a scalable pipeline orchestration for parallel inference. Specifically, the DiT blocks are partitioned across devices. As illustrated in Fig. 6, each device processes its input sequence as a micro-step and transmits the results to the next stage within a ring structure. These enable consecutive stages of the model to operate concurrently in a pipeline-parallel manner, achieving near-linear acceleration for DiT throughput.
In addition to the static partition, we find that VAE encoding and decoding create an unequal distribution of tasks across GPUs. To enhance throughput, we propose a scheduler that reallocates blocks across devices dynamically using inference-time measurements. These methods allow for competitive real-time generation performance on standard GPUs, thus reducing the barrier for practical implementation.
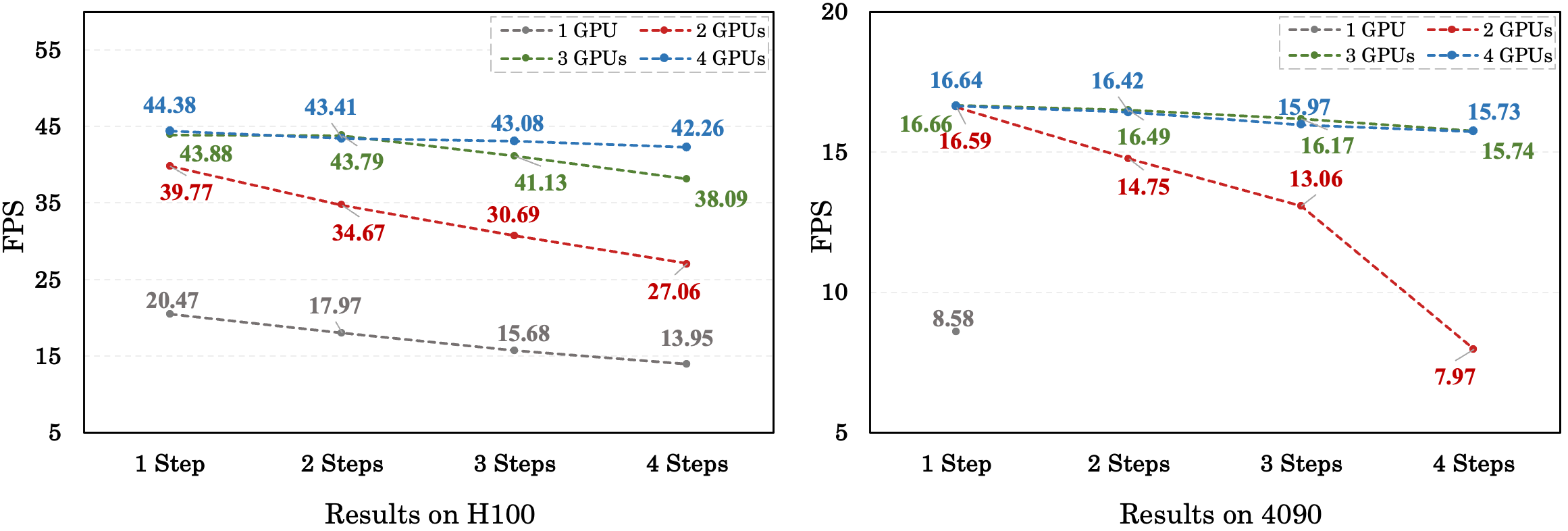
Fig. 7: The throughput results of the 1.3B model on H100 GPUs (with NVLink) and 4090 GPUs (with PCIe)

Fig. 8: The throughput results of the 14B model on H100 GPUs (communicate through NVLink)
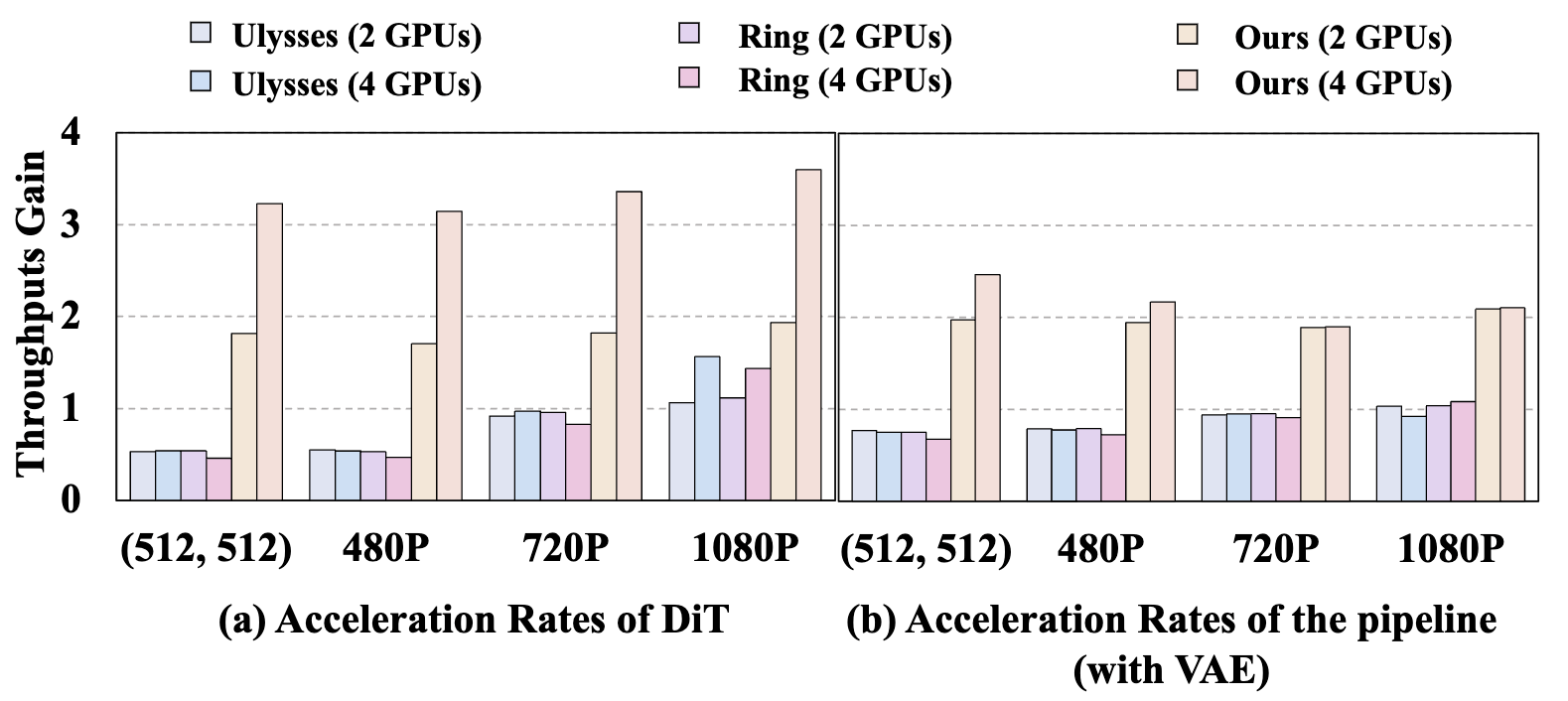
Fig. 9: Acceleration rate of different approaches on various resolutions. Left: Testing the acceleration rate of DiT only. Right: Testing the acceleration of the whole pipeline (with VAE).
Acknowledgements
StreamDiffusionV2 is inspired by the prior works StreamDiffusion and StreamV2V. Our Causal DiT builds upon CausVid, and the rolling KV cache design is inspired by Self-Forcing.
We are grateful to the team members of StreamDiffusion for their support.
BibTeX
@article{feng2025streamdiffusionv2,
title={StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation},
author={Feng, Tianrui and Li, Zhi and Yang, Shuo and Xi, Haocheng and Li, Muyang and Li, Xiuyu and Zhang, Lvmin and Yang, Keting and Peng, Kelly and Han, Song and others},
journal={arXiv preprint arXiv:2511.07399},
year={2025}
}